In this post, I’ll walk through the framework and architecture of my project, explain the module separation, and share why I structured the system in this way.
I have been already made a mini database project in Go, but it has been a long time and I want to re do it again and then in a new language i just picked up.
Here’s the overall system design (as of now):
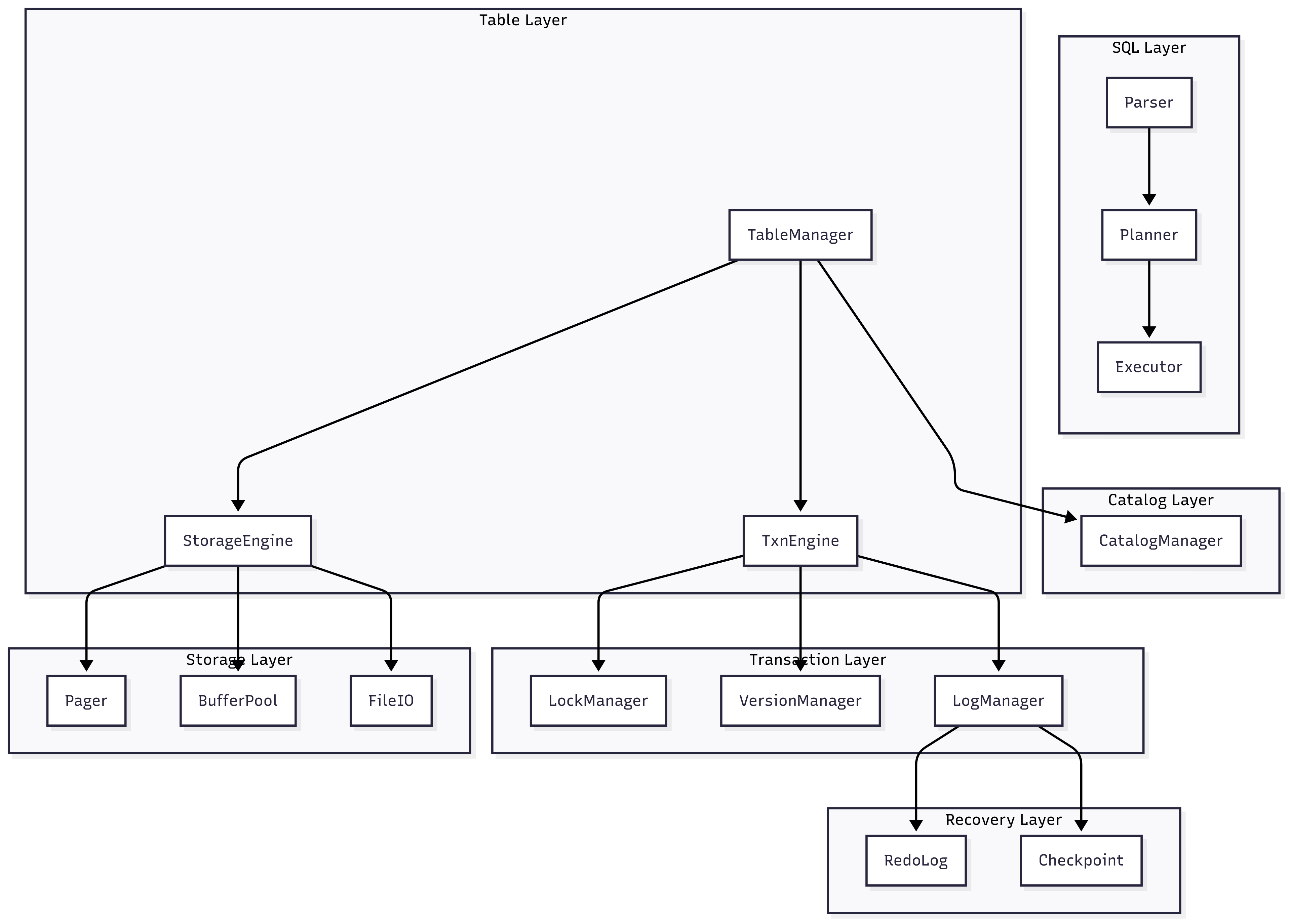
This diagram shows how the different modules depend on each other. At the top, SQL commands enter through the Parser → Planner → Executor pipeline, eventually touching the lower-level layers that deal with tables, transactions, storage, and recovery.
At a high level, the system is divided into layers:
So with the overall design, we can set the structure of the project:
1 | ├── Catalog |
TableManager.Users think in SQL, not in storage pages. By isolating the SQL pipeline (Parser → Planner → Executor), I can extend SQL support without touching storage or transactions.
1 | namespace LiteDatabase.Sql; |
1 | namespace LiteDatabase.Sql; |
1 | namespace LiteDatabase.Sql; |
CatalogManager: Manages metadata (schemas, table definitions, column types).This is crucial because a database needs to know what tables exist and what their structure looks like. Without a catalog, every query would need hardcoded assumptions.
1 | // ICatalogManager.cs |
I use interface in case I need to switch to different test implementations.
TableManager: The main entry point for managing tables. Exposes the logical API for table operations: create, insert, scan. It coordinates with both the StorageEngine and TxnEngine, as well as the CatalogManager.This is the bridge between SQL and the internals. SQL queries should never directly touch the storage engine. Instead, they go through the TableManager, which orchestrates the correct calls to lower layers.
1 | // ITableManager.cs |
TxnEngine: Handles transaction lifecycle (start, commit, abort).LockManager: Provides concurrency control by locking rows or tables.VersionManager: Enables multi-version concurrency control (MVCC).LogManager: Records logs for durability and recovery.Transactions are orthogonal to storage. You can design a storage engine without transactions, but without a transaction system you can’t guarantee ACID properties. That’s why this layer is isolated.
1 | // ITxnEngine.cs |
1 | namespace LiteDatabase.Transaction; |
1 | namespace LiteDatabase.Storage; |
1 | using LiteDatabase.Recovery; |
StorageEngine: High-level interface to physical storage.Pager: Manages pages of data on disk.BufferPool: Caches frequently used pages in memory.FileIO: Handles raw file operations.Databases deal with pages, not raw bytes. That’s why Pager/BufferPool are key abstractions: they allow efficient disk access and caching.
1 | // IStorageEngine.cs |
1 | namespace LiteDatabase.Storage; |
1 | namespace LiteDatabase.Storage; |
1 | namespace LiteDatabase.Storage; |
RedoLog: Ensures durability; after a crash, operations can be replayed.Checkpoint: Periodically flushes data to reduce recovery time.Recovery is not needed in normal operation, but is essential after a crash. If recovery logic were embedded directly in the transaction layer, it would complicate everyday code. By isolating it, the normal execution path remains simple, and failure-handling is contained.
1 | namespace LiteDatabase.Recovery; |
1 | namespace LiteDatabase.Recovery; |
We’ve set up the structure, now is to initialize then inMain.
1 | using LiteDatabase.Catalog; |
Currently, the project has the skeleton in place, with dependencies and initialization wired up. The next milestone is to implement the SQL Layer (Parser, Planner, Executor), starting with a small subset of SQL:
CREATE TABLEINSERT INTOSELECT *From there, I’ll gradually flesh out the Storage and Transaction layers to support ACID semantics.
This project is my attempt to demystify database internals by building one myself. The current design focuses on clarity and modularity, with each layer serving a specific role. While the system is far from production-ready, it already reflects the architecture patterns used in real-world relational databases.
Stay tuned for the next post, where I’ll dive into building the SQL Parser and running the first queries end-to-end!

