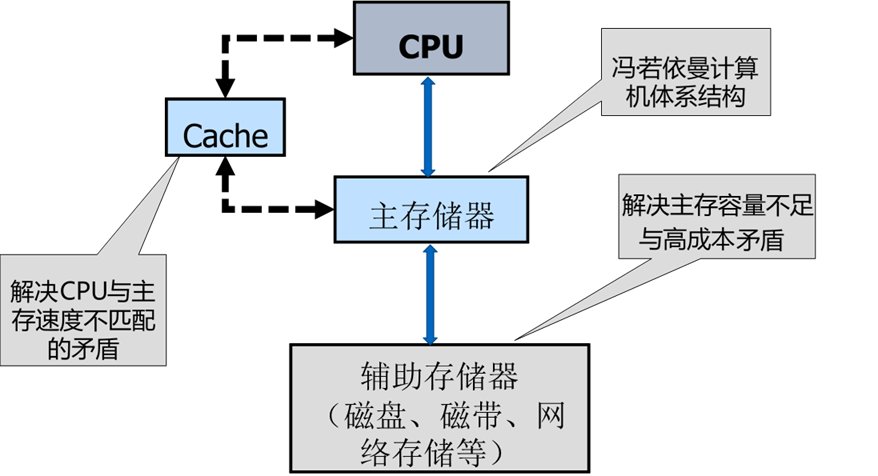
存储系统是指计算机中由存放程序和数据的各种存储设备、控制部件及管理信息调度的设备(硬件)和算法(软件)所组成的系统。计算机的主存储器不能同时满足存取速度快、存储容量大和成本低的要求,在计算机中必须有速度由慢到快、容量由大到小的多级层次存储器,以最优的控制调度算法和合理的成本,构成具有性能可接受的存储系统。
原理
存储程序 (主存)
程序控制(CPU)
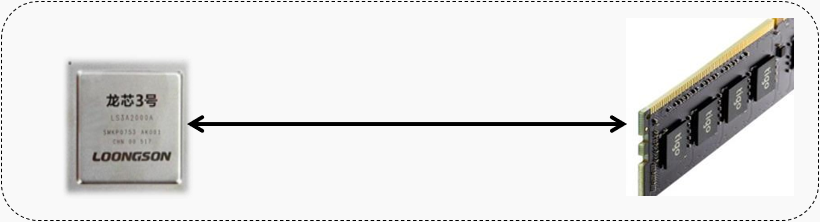
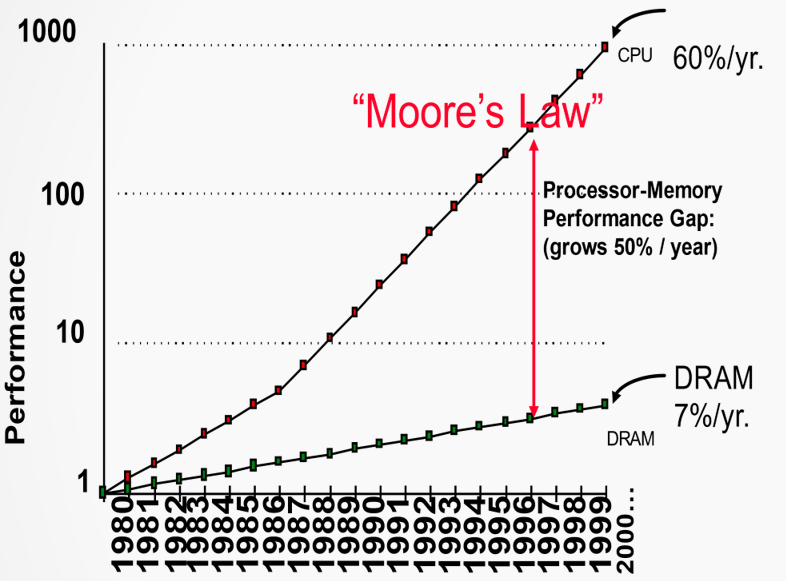
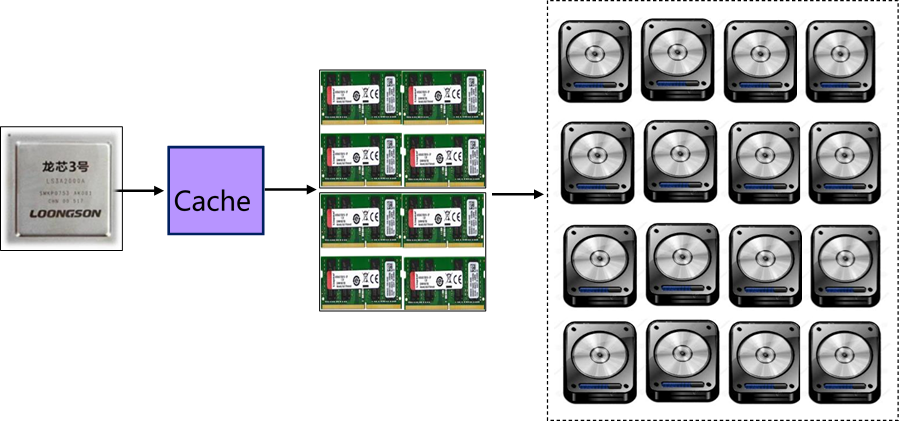
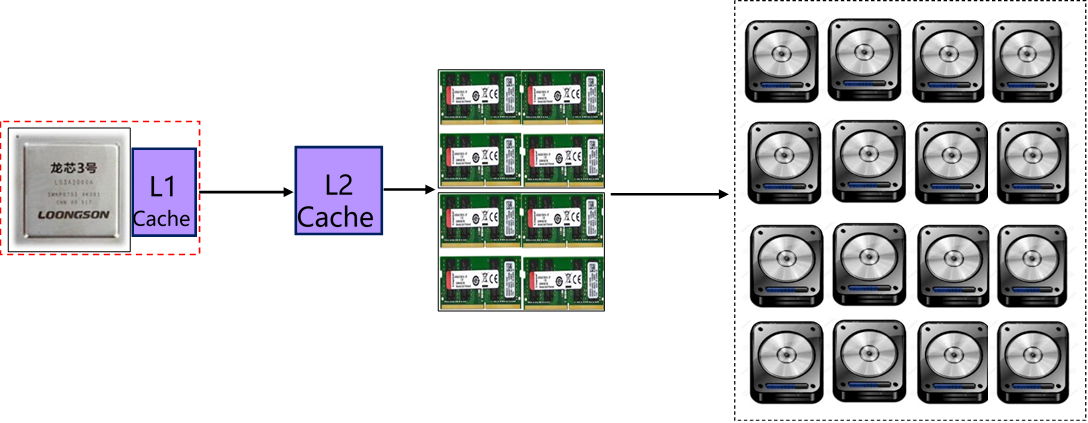
CPU访问到的存储系统具有Cache的速度,辅存的容量和价格
高速缓存又分为两部分
局部性原理
时间局部性: 现在被访问的信息2在不久的将来还将再次被访问
时间局部性的程序结构体现:循环结构
空间局部性:现访问信息2 ,下一次访问2附近的信息。
空间局部性的程序结构体现:顺序结构
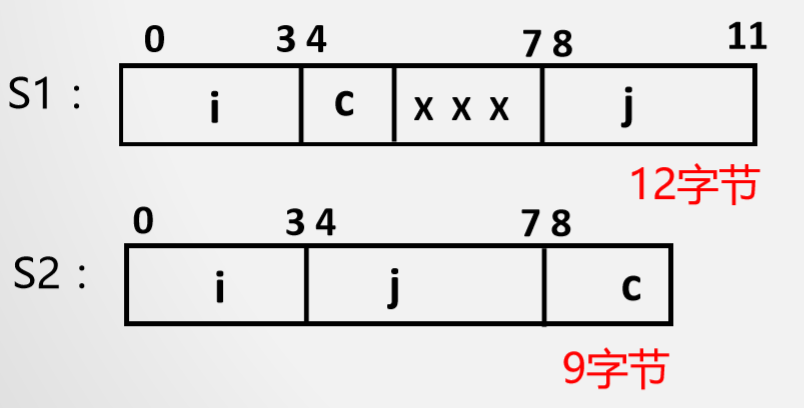
边界也分好几种:字节边界,字边界,双字边界,半字长边界.
int i(32位), short k(16位), double x(64位), char c(8位), short j,…… (32位系统中)
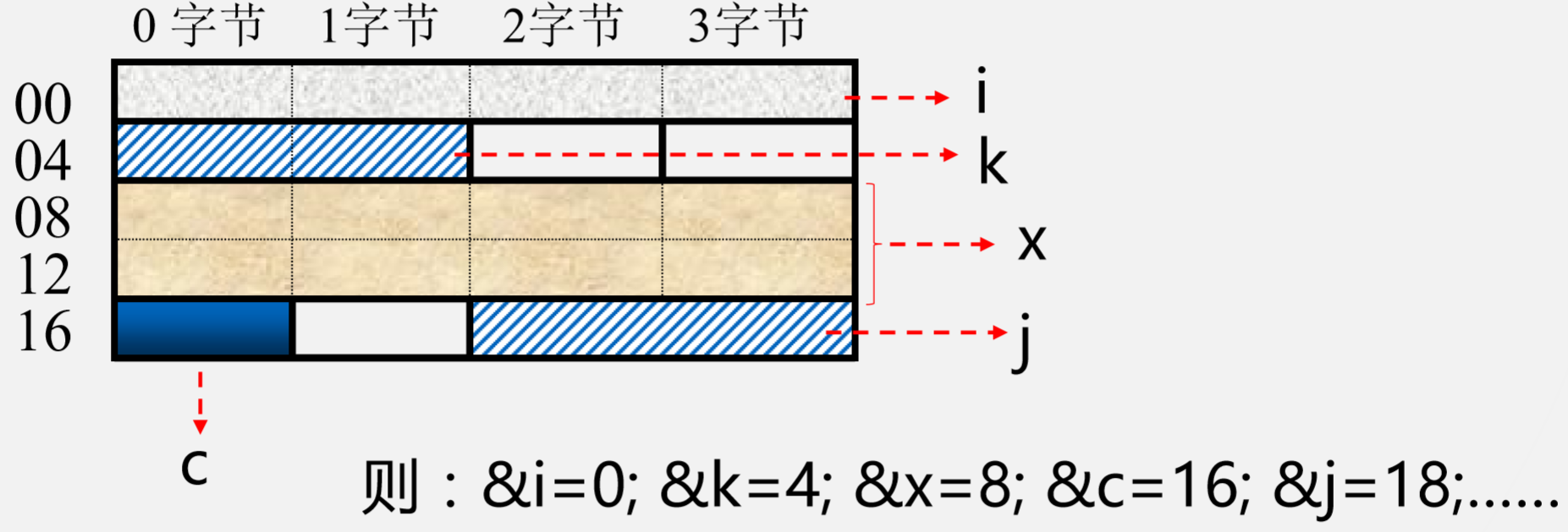
边界存放可能会导致部分空间的浪费.
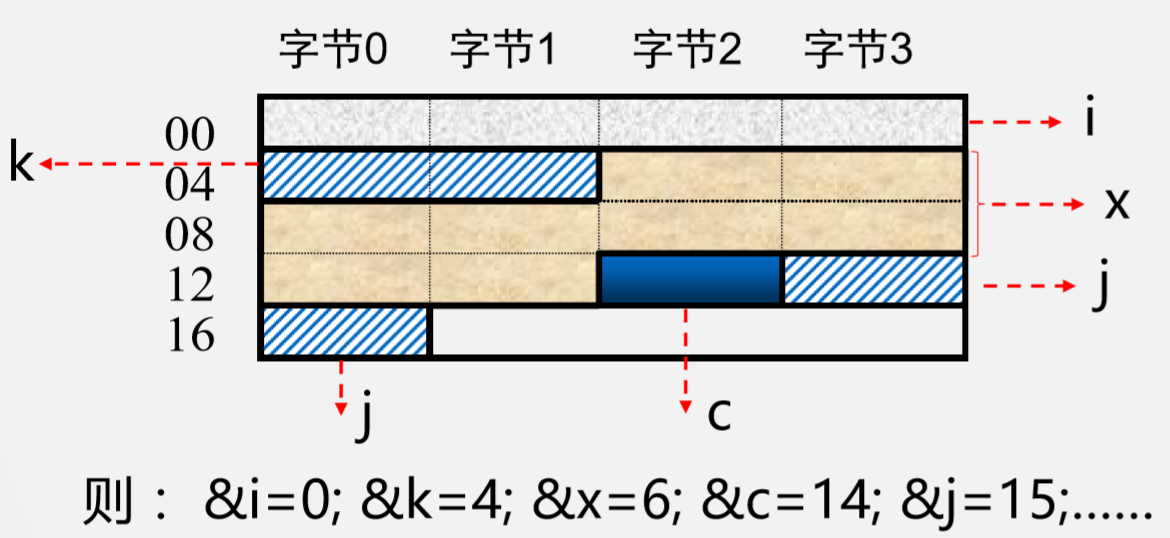
虽节省了空间,但增加了访存次数!需要在性能与容量间权衡!
比如要访问x,则需要访问三次,而刚才只需要访问两次.所以这个是用性能换空间.
双字长数据边界对齐的起始地址的最末三位为000(8字节整数倍)
双字长是64位,即八个字节,计算机中主存按字节,所以是八字节的整数倍.
单字长边界对齐的起始地址的末二位为00(4字节整数倍)
半字长边界对齐的起始地址的最末一位为0(2字节整数倍)
对齐情况下,哪种结构声明更好(32位为例)

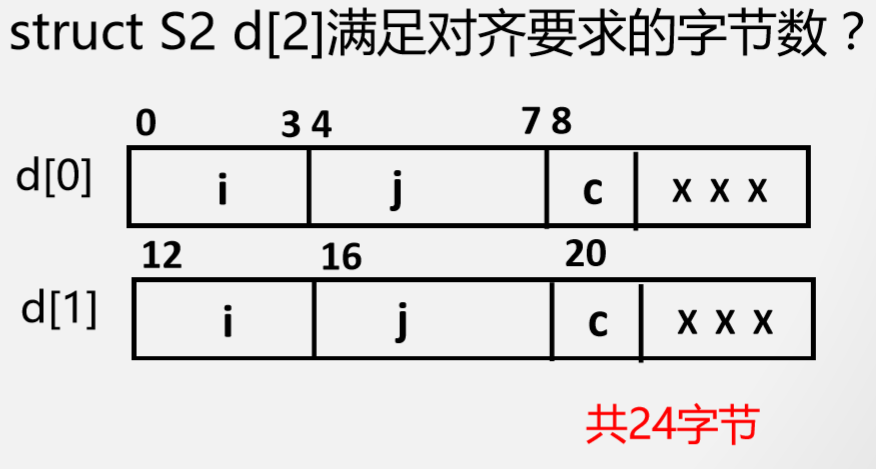
如果每个只有一个的话,是第一种结构更好,但是如果是多维数组的话,两种方式没什么区别,因为都有浪费的地方。
Big-endian:最高字节地址(MSB)是数据地址

Big-endian: 最高字节地址(MSB)是数据地址

设某程序执行前 r0 = 0x 11223344,执行下列指令:
1 | r1 = 0x100 |
小端模式下:r2=0x44
大选模式下:r2=0x11
无论是大端还是小端,每个系统内部是一致的,但在系统间通信时可能会发生问题!因为顺序不同,需要进行顺序转换;
任何存储器都是由存储单元按照某种模式组合起来的。
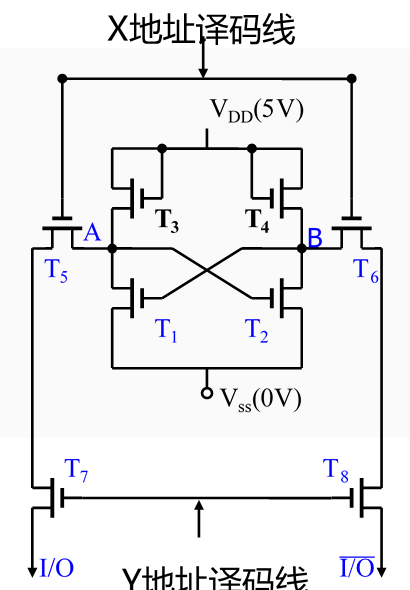
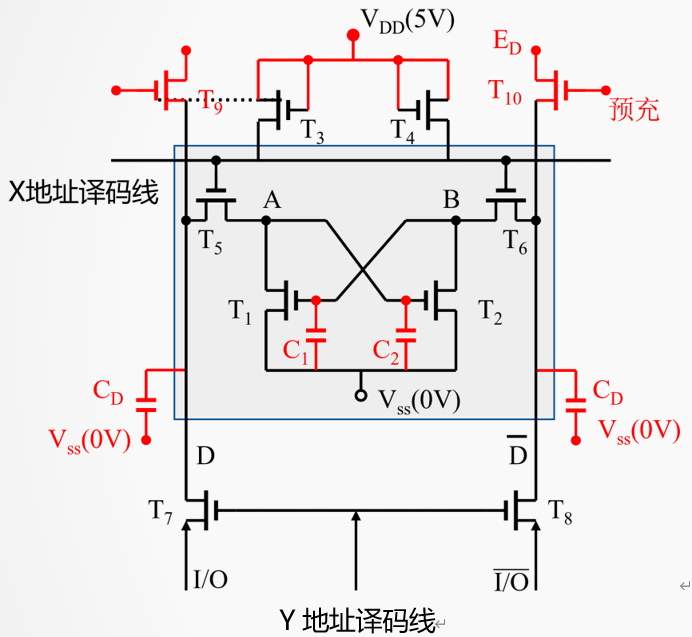
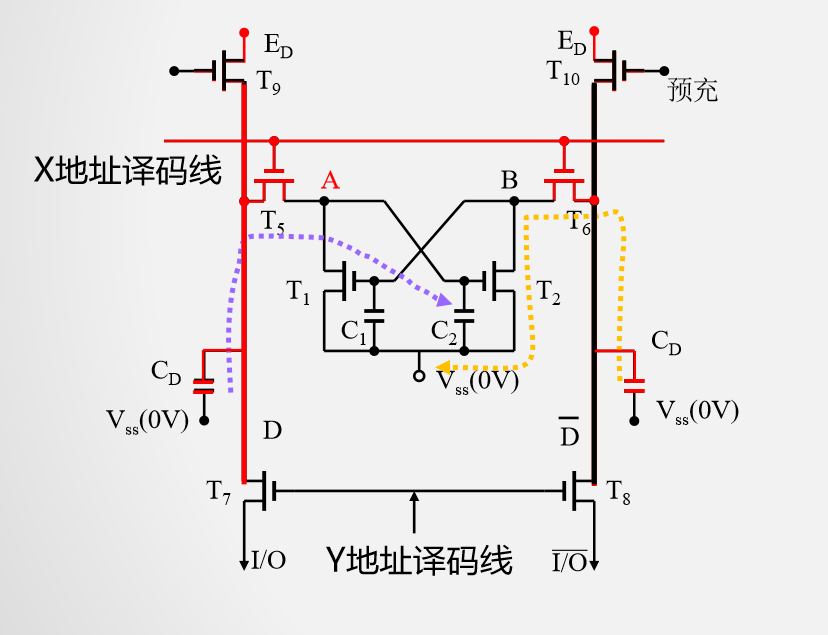
当X地址选通时(行选通)
Y地址选通(列选通)
写过程
X有效→ T5、 T6 通→ A与 I/O 连通
Y有效→ T7、 T8 通 → B与$\overline{I / O}$连通
假定I/O端是高电平,$\overline{I / O}$是低电平,写入的是1,当X,Y都有效时,A点是高电位。
A点是高电位,T1饱和导通,Vss接地,所以B通过T2接地。所以T1是低点位,不饱和导通,维持A点高电位。
写入的是0则相反。
读过程
X有效→ T5、 T6 通→ A与 I/O 连通 1
Y有效→ T7、 T8 通 → B与 $\overline{I / O}$ 连通 0
通过外接于I/O与$\overline{I / O}$间的电流放大器中的电流方向可判断读出的是1还是0(与写入时定义的1和0有关)
如果写入的是0,X,Y有效时,A点低电平,B点高电平
如果写入的是1,X,Y有效时,B点低电平,A点高电平
无论是读写,X,Y译码线必须同时有效
X、 Y撤销后,由负载管 T3、 T4 分别为工作管T1、 T2 提供工作电流,保持其稳定互锁状态不变。
T2饱和导通,T4为它提供工作电流。T1同理。
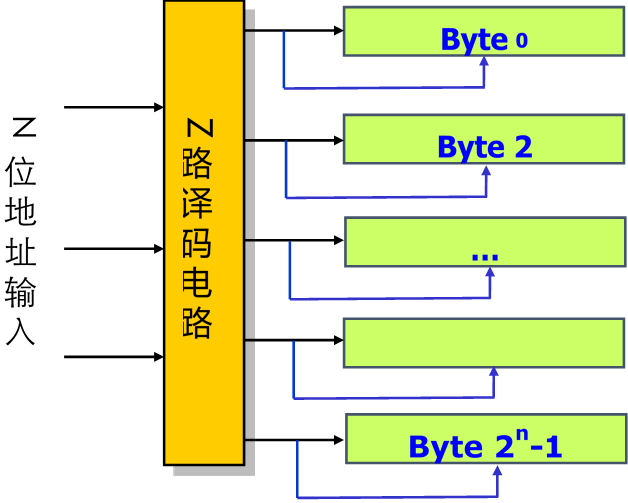
N位地址,寻址$2^n$个存储单元,2n根译码线
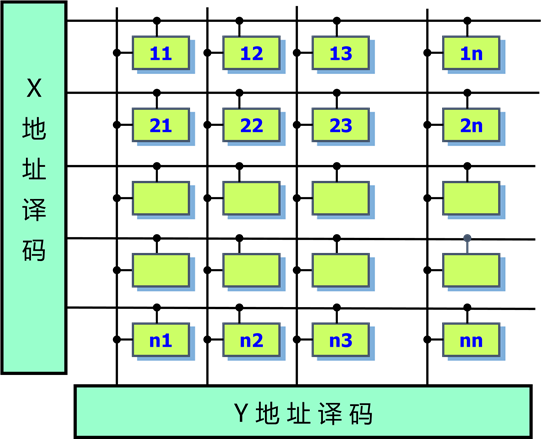
N位地址,寻址$2^n$个存储单元,$2^{2(n/2)+1}$根译码线
由于每行每列有多个单元,实际应用中,地址译码器输出后面加驱动放大电路。
双译码结构的好处:减少地址译码线的输出数量
举例:双译码存储器
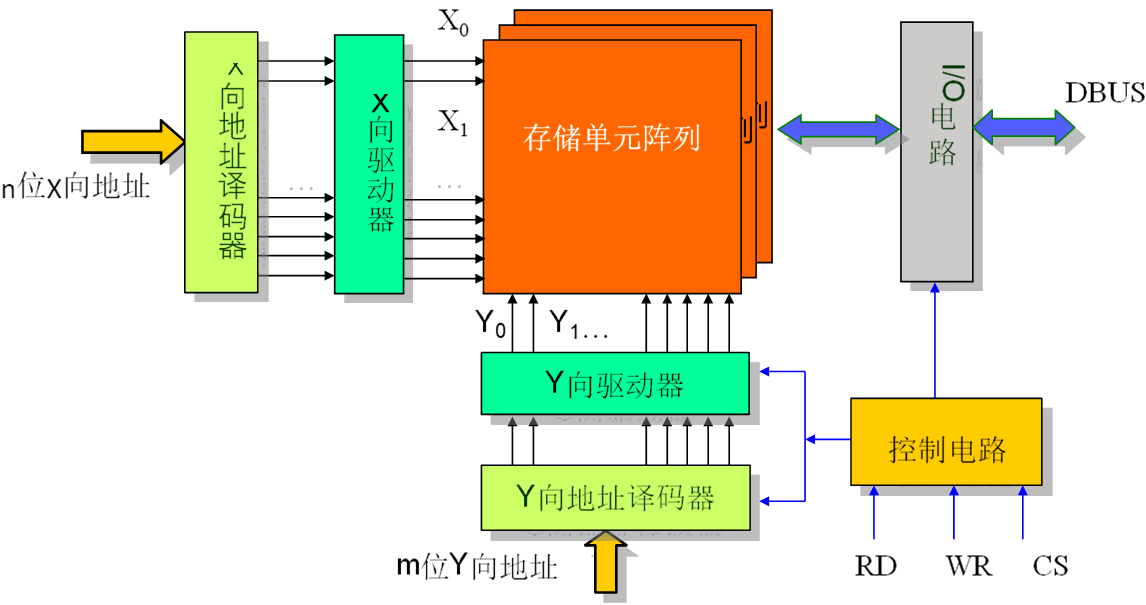
具体的存储芯片
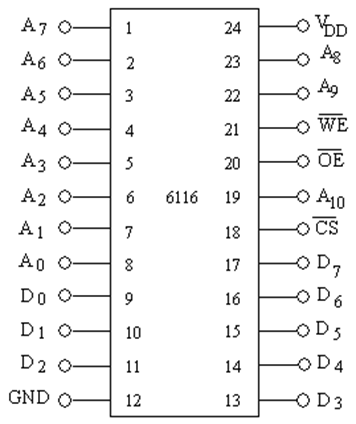

2114内部结构图
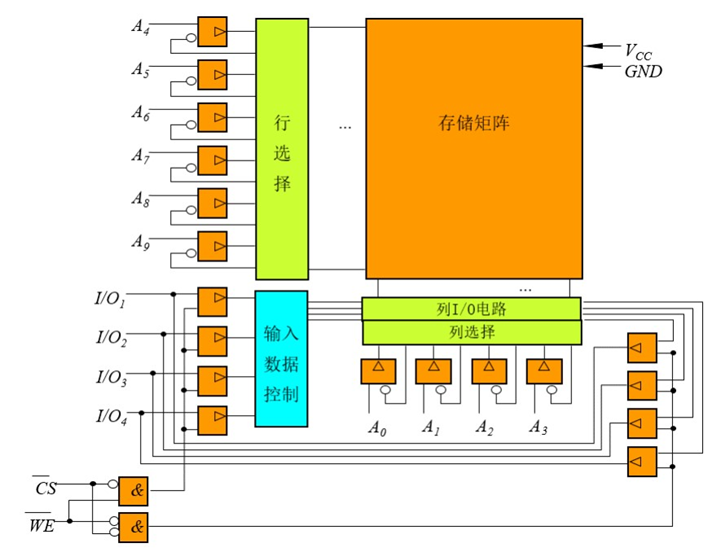
列选通有四位,就可也表示2的4次方=16列。相当于第一列物理地址的编号是0000,第二列物理地址的编号是0001……
所以静态存储器芯片容量较小。
解决SRAM不足采取的方法:
Y地址选通
X地址选通
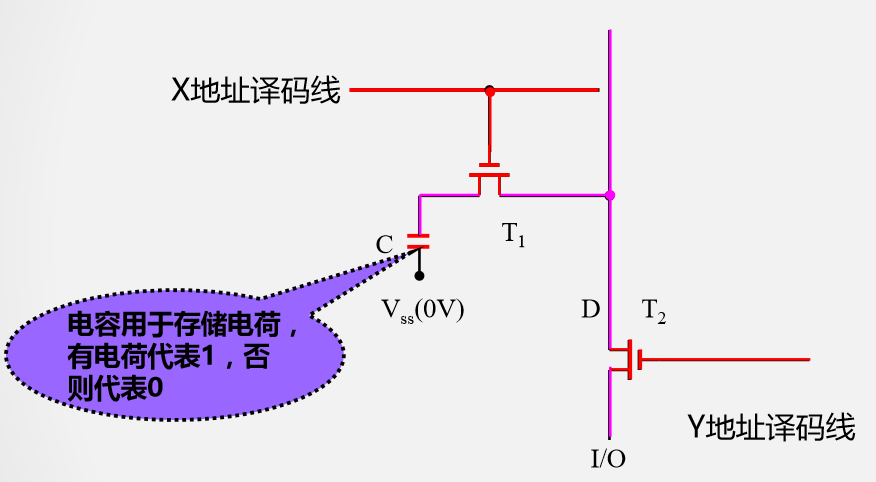
假定I/O端为高电平,写入1,A点饱和导通同时还给C2充电。
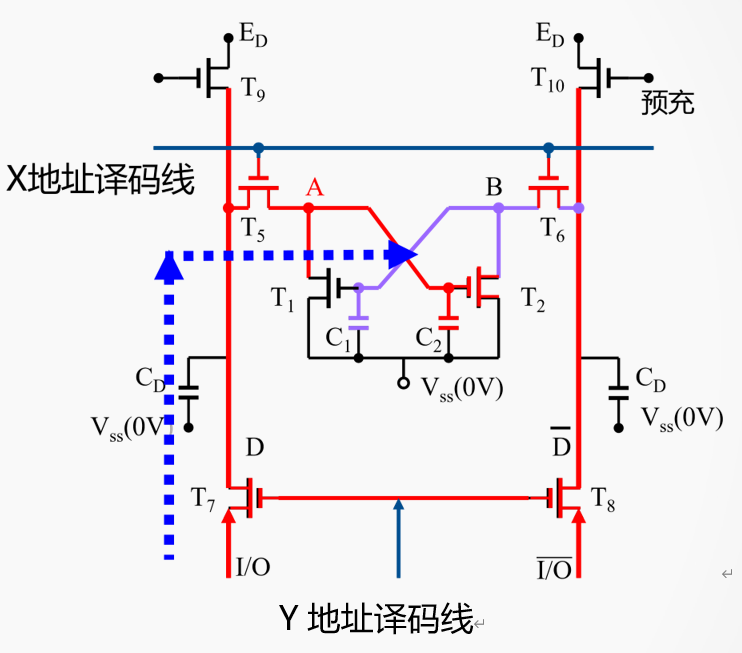
C2上的电量太少,不足以判断写入的数据。所以不能采用静态的方法。
给出预充信号
撤除预充信号
X地址选通
Y地址选通
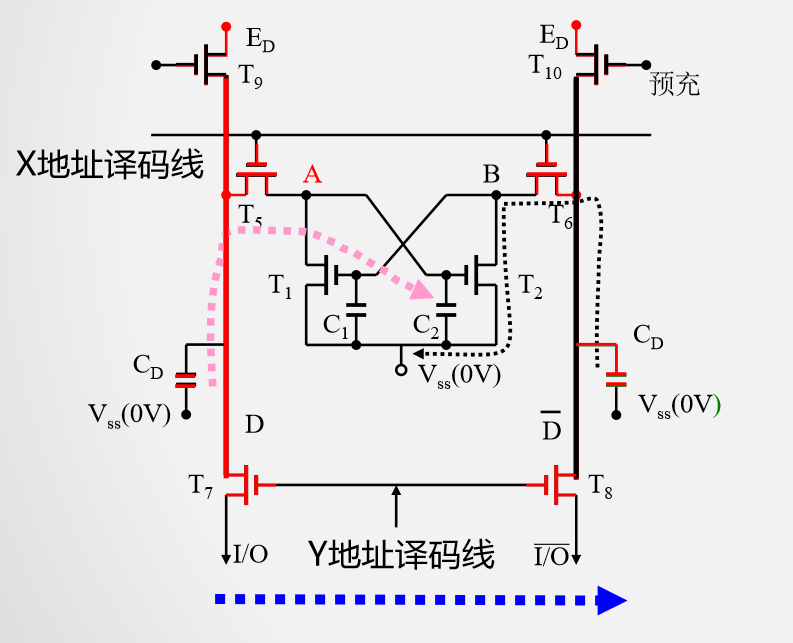
读过程比写复杂、速度慢
由于没有T3,T4,稳定的状态只能由C1,C2来维持,但只能维持几毫秒,所以必须尽快充电防止信息消失。
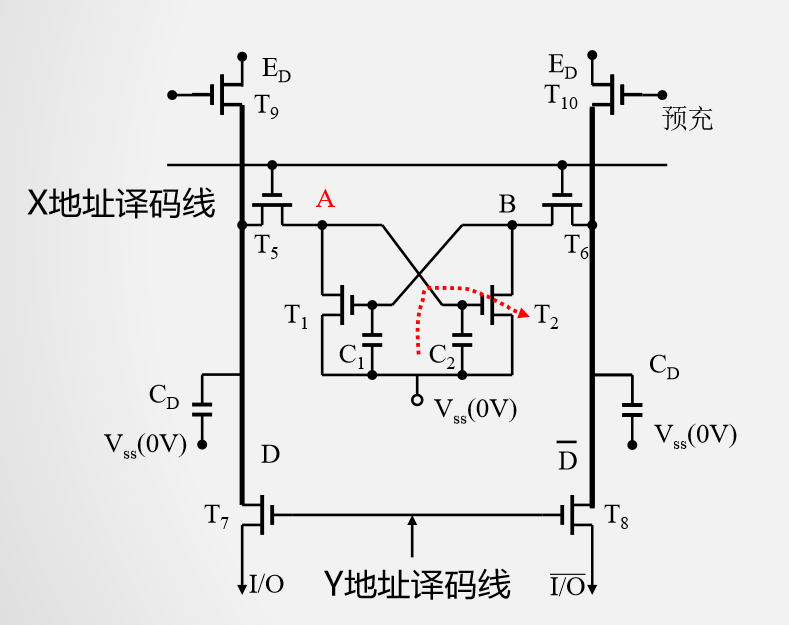
给出预充信号
撤除预充信号
X地址选通
假定刷新周期为2ms, DRAM 内部128行,读写周期0.5µs

集中刷新期间,CPU不能访问存储器,否则会导致相关行的内容丢失。
采用集中刷新的存储器平均读写周期 $\overline{T} = 2ms/(4000-128) = 0.5165 \mu s$
集中刷新可以保持存储单体的高速特性

读写周期由$0.5 \mu s$变成$0.1 \mu s$
$\overline{T} = 1 \mu s$
分散刷新没有保持存储单体的高速特性,由于刷新次数2000大于需要刷新的次数128。

将2ms分成128段,每段约$15.5 \mu s$,每段用最后一块刷新。
$\overline{T} = 2ms/(4000-128) = 0.5165 \mu s$

动态读写单元行选通和列选通分开了,因为刷新按照行刷新不需要列选通。
数据的入和出是两个不同的引脚
DRAM: 地址线复用,$\overline{RAS}$兼为片选信号
进一步提高密度,剪裁冗余电路,核心是电容
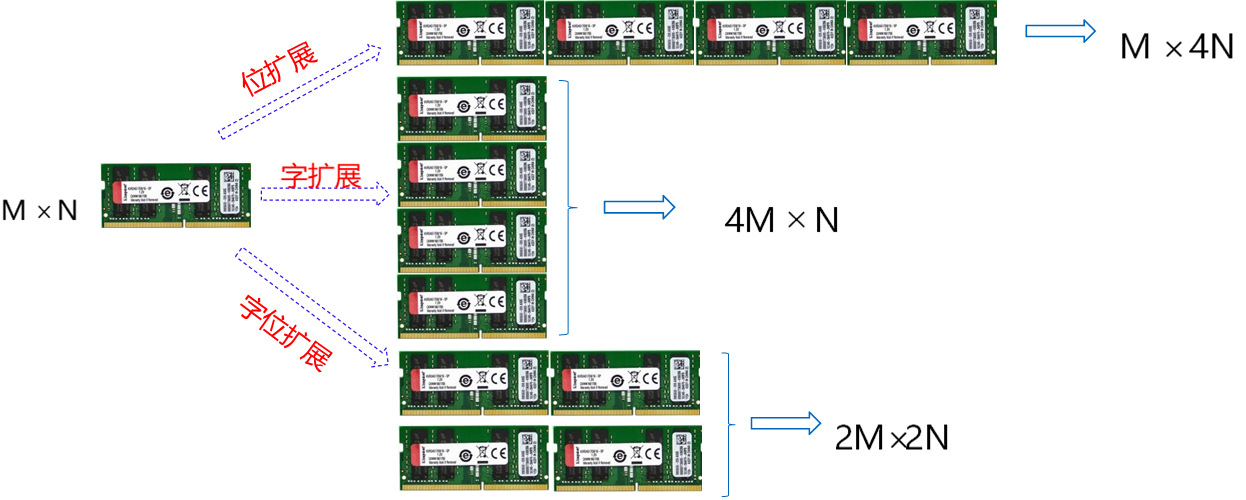
无论哪种类型的存储扩展都要完成CPU与主存间地址线、数据线、控制线的连接
例1 用$16K \times 8$芯片构建$16K \times 32$的存储器
所需芯片数量:16K*32/(16K *8) =4
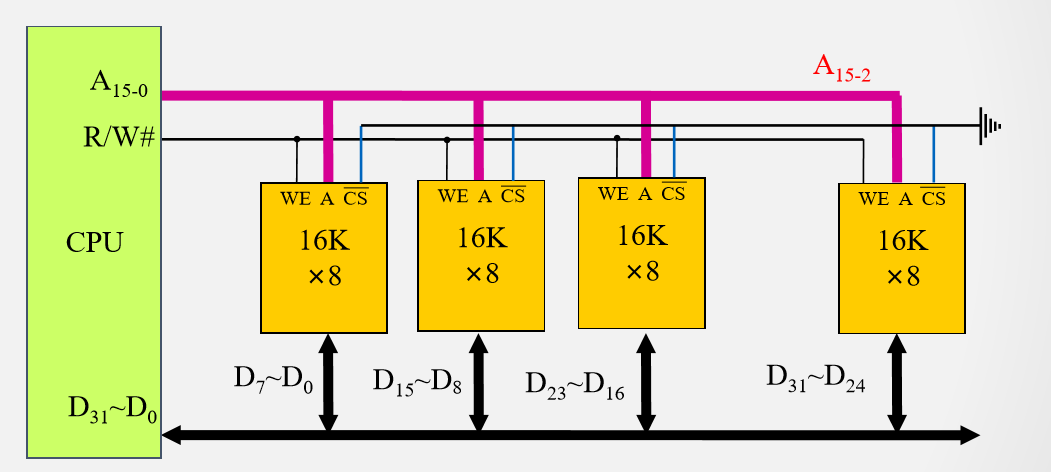
所有存储芯片并行工作,贡献32位数据中的不同8位
例2 用$16K \times 8$的存储芯片构建$128K \times 8$的存储器
所需芯片数量:128K * 8/ (16K*8) = 8
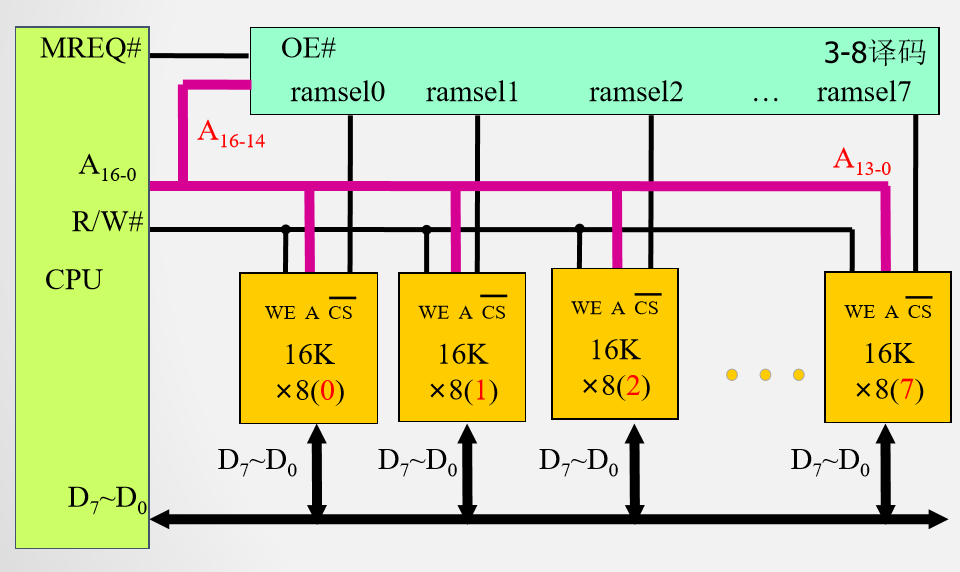
计算每片的全局地址空间
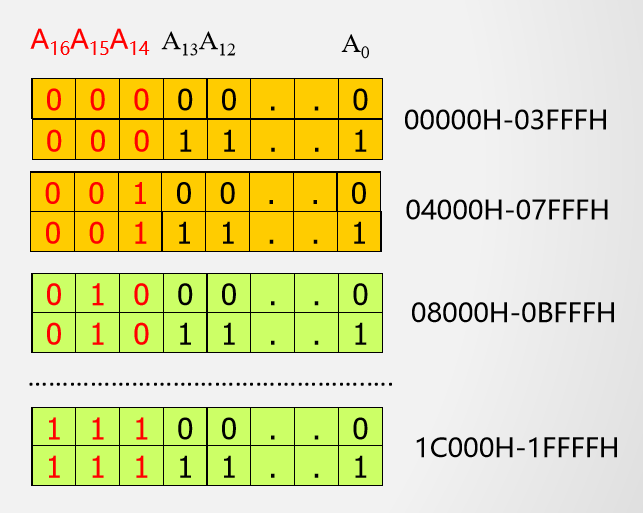
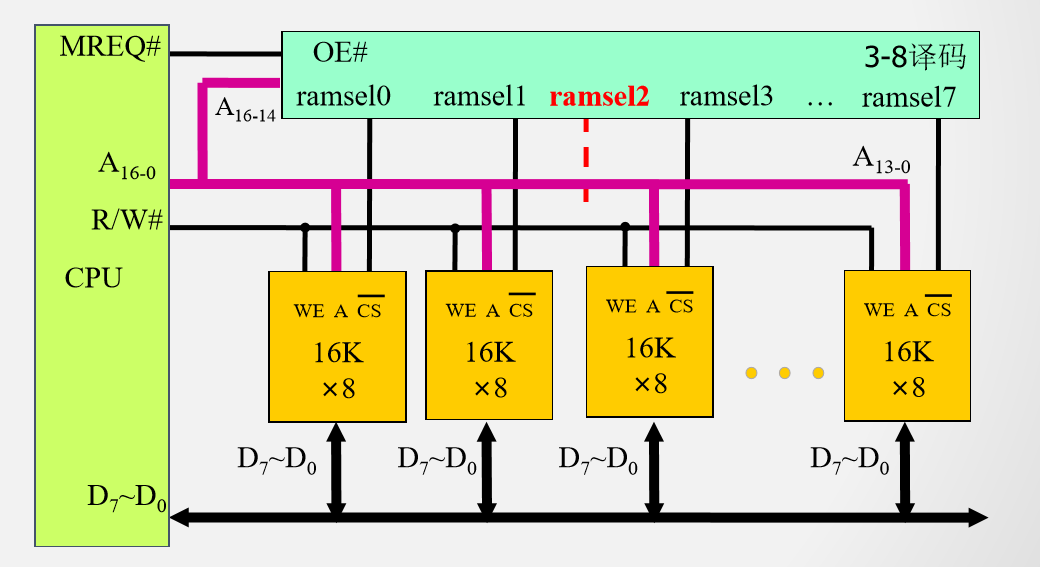
例3 用$16K \times 8$的存储芯片构建$128K \times 8$的存储器,其中08000H~0BFFFH存储空间保留不用


所需芯片数量:(128K-16K)*8/(16K * 8)= 7
例4 用$16K \times 8$ 的存储芯片构建$128K \times 32$的存储器
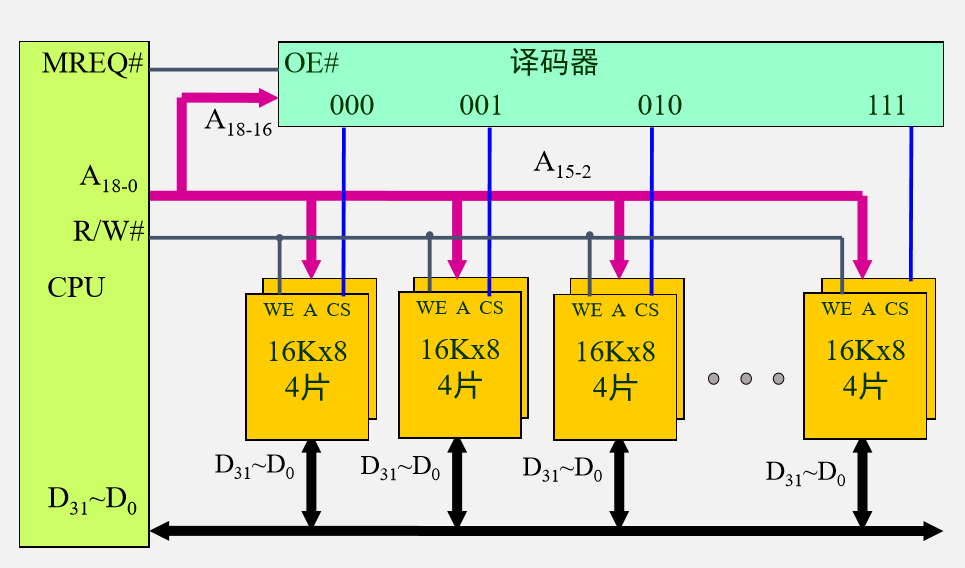
其基本思想是在不提高存储器速率、不扩展数据通路位数的前提下,通过存储芯片的交叉组织,提高CPU单位时间内访问的数据量,从而缓解快速的CPU与慢速的主存之间的速度差异。
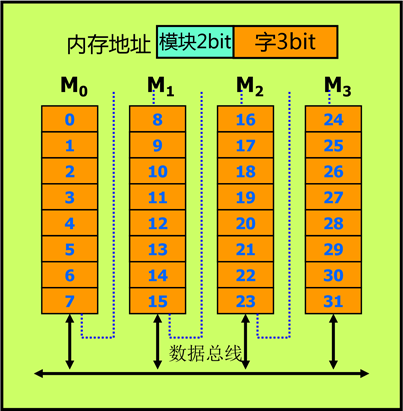
由图中可知,内存地址一共五个bit,一共有四个存储芯片,每一个存储芯片的容量是八个存储单元。由于$2^3=8$,所以,需要三个bit就能表示八个不同的位置。剩下两个bit正好做片选信号。$2^2=4$两个bit表示四种状态正好对应四个存储芯片。
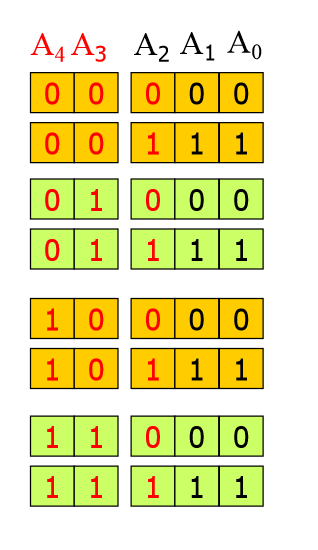
这种方式有几个特点:
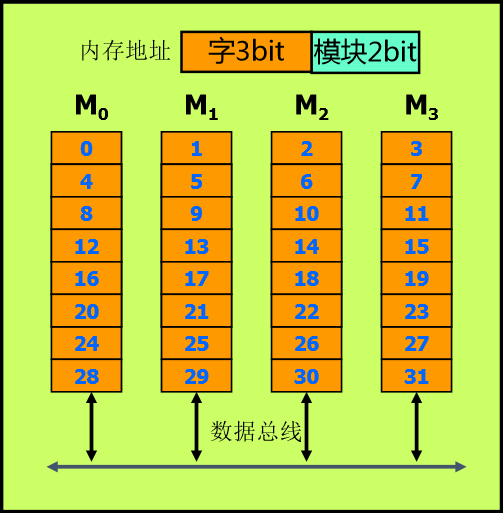
与高位不同的是,它采用高位三位表示地址,低2位做片选信号。
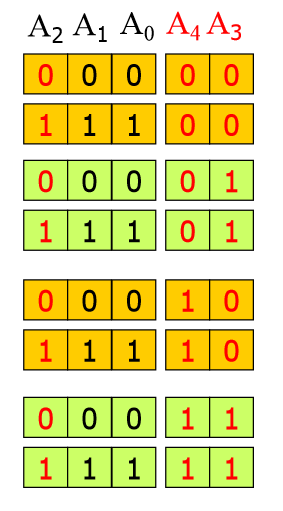
这样的话000000在第一个芯片, 000001就在第二个芯片。
这种方式的特点是:
低位多体交叉存储器得为每一个单体配置单独地址寄存器
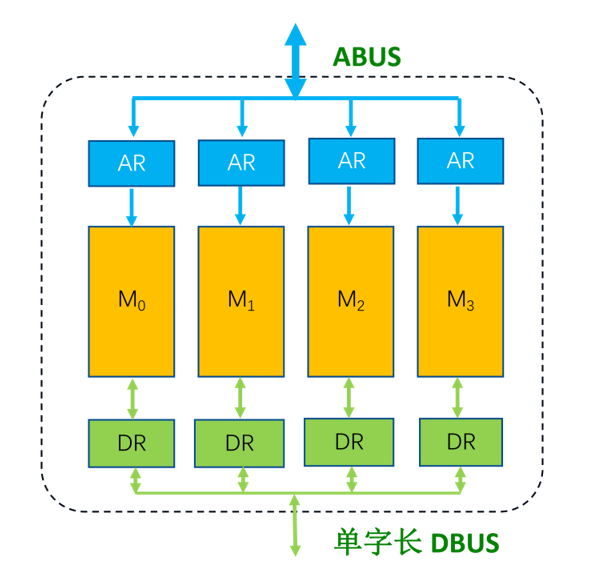
送完第一个数据的地址,可以接着送第二个数据的地址(在第二片上)。等到第四个地址送完后,第一个数据的地址存储访问也已经完成,然后就依次取第一个数据,第二个等等。
定量分析:
设,存储周期为T,总线传输周期(CPU把地址传到每一个芯片的AR的传输周期为$\tau$),多体交叉的模块数量为m个。流水线方式存取的条件:$T=m \tau$
只有满足上述关系,才能实现流水线的并行工作。即每个模块启动后经过 $\tau$ 时间的延时,就可以启动下一个模块。
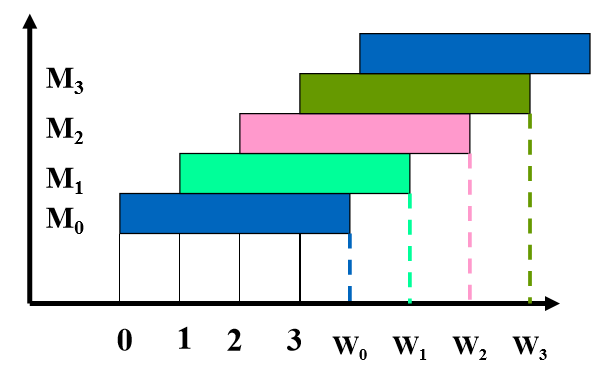
虽然每一个存储单体的周期没变,但是由于并行原理,单位时间内访问的数据量变大了。计算可知。
连续并行读m个字的时间:$t_1=T+(m-1) \tau$
顺序读m个字的时间:$t_1=Tm$

